Antlr4学习笔记
ANTLR简介
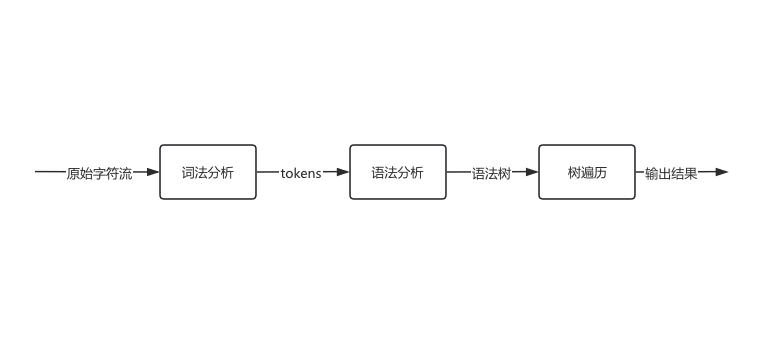
工作原理
1、编写语法规则文件(.g4)
定义一个.g4文件,包含两类规则
1 、词法规则(Lexer Rules):定义如何将输入字符流拆分成词法单元(Token)
// 示例:定义整数和运算符的词法规则
INT : [0-9]+;
PLUS : '+';
2 、语法规则(Parser Rules):定义如何将词法单元组合成语法结构
// 示例:定义加法表达式的语法规则
expr : INT PLUS INT;
2、词法分析
词法分析(Lexing):将输入文本转换成Token流
1
输入 "1+2" → Token流 [INT(1), PLUS(+), INT(2)]
词法分析器原理主要是基于正则表达式和有限自动机,有以下特点:
有限自动机:描述状态转移的数学模型,分确定性有限自动机(DFA)和非确定性有限自动机(NFA)
贪婪匹配:总是匹配最长的有效字符序列
优先级规则:定义在前面的规则优先级更高
3、语法分析
语法分析(Parsing):根据语法规则验证Token流合法性,并构建解析树(Parse Tree)或抽象语法树(AST)
1
Token流 → 解析树 (expr (INT 1) (PLUS +) (INT 2))
语法分析器原理主要是基于 自适应 LL(*) 算法,将 Token 流转化成语法分析树。
什么是自适应 LL(*)算法?
动态向前看 k 个 token,直到能够做出决策。
4 、求值,遍历语法树(todo)
监听器(Listener)/访问者(Visitor):遍历语法树,执行自定义逻辑
| 设计模式 | Listener | Vistor |
|---|---|---|
| 遍历控制 | 自动遍历(深度优先) | 手动控制 |
| 返回值 | 无 | 有,返回给父节点 |
| 特点 | 对于每个节点有 Entry_xx和 Exit_xx方法 | 只有 Visit_xx方法 |
| 使用场景 | 不需要返回值,如:json 解析 | 表达式解析 |
什么是Visitor设计模式?
答:
什么是Listener设计模式?
答:
ANTLR常见问题
递归问题
直接递归:语法规则的产生式中引用自身,如:
1
expr : expr '+' term | term;
间接递归:语法规则 1 引用语法规则 2,语法规则 2 又引用语法规则 1,如:
1
2
expr1 : expr2 | term;
expr2 : expr1 | term;
左递归:产生式中递归引用的语法规则在左侧,如:expr在产生式的最左侧
1
expr : expr '+' term | term;
右递归(其他递归):除左递归外的其他递归
1
expr : term | term '+' expr;
antlr4不支持间接左递归,为什么?
不支持间接左递归是设计选择,而不是技术限制;出现间接左递归通常是语法规则设计不清晰,复杂等问题。可以通过合并规则转化成直接递归
antlr4是如何支持直接左递归?
ANTLR 4使用改进的Packrat解析器和自适应LL(*)算法来转化成等价的非递归形式。
ANTLR工具生成代码
运行ANTLR工具,根据语法文件(.g4)文件生成以下代码:
- 词法分析器(Lexer):将输入文本转换成Token流
- 语法分析器(Parser):根据语法规则验证Token流合法性,并构建解析树(Parse Tree)
- 监听器(Listener)/访问者(Visitor):遍历解析树,执行自定义逻辑