Kafka
Kafka
总体架构
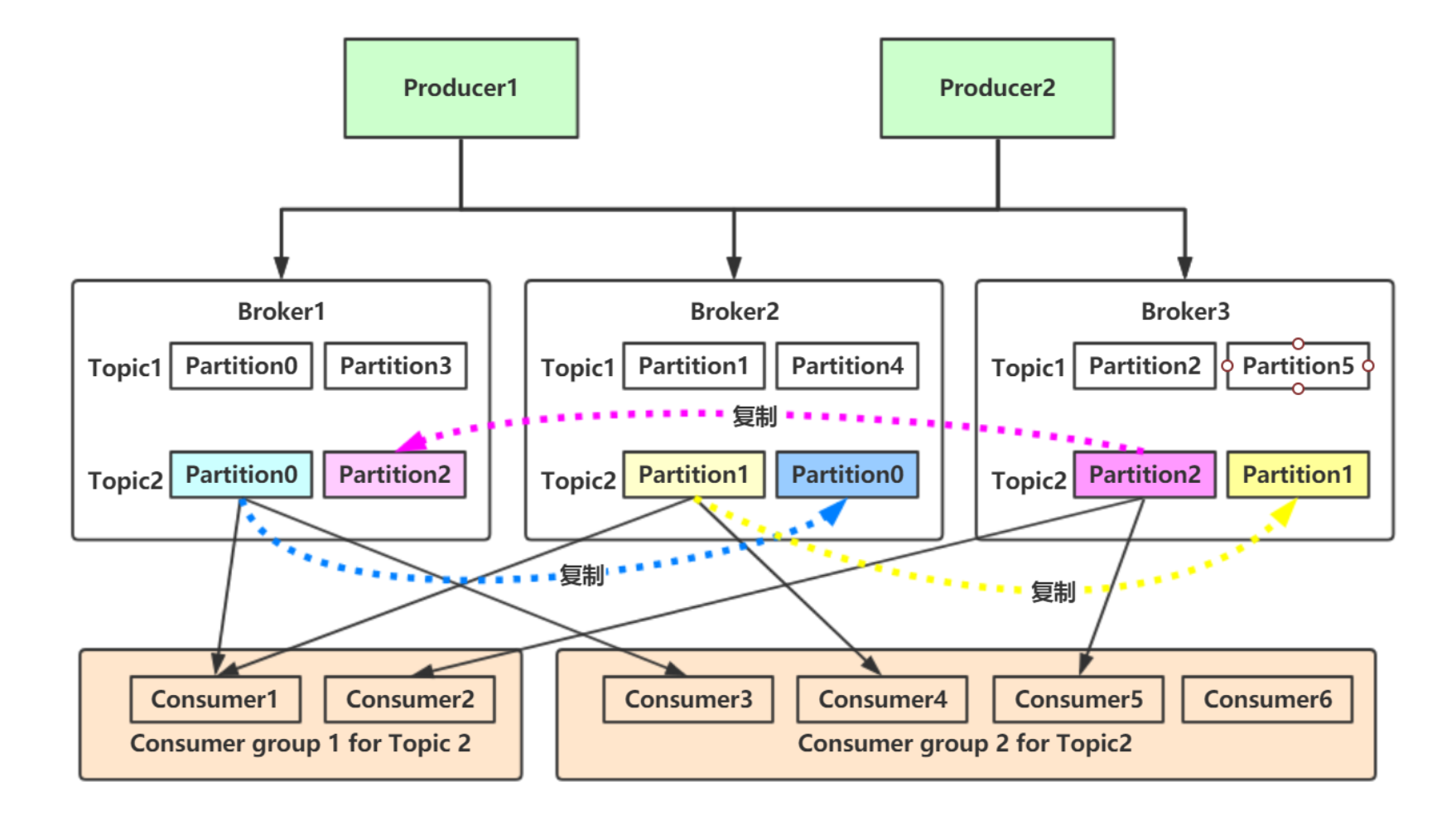
- Producer:生成消息,push到Topic
- Broker:每个节点就是一个Broker,负责创建Topic,并将Topic中消息持久化到磁盘
- Topic:同一个Topic可以分布在一个或多个Broker,一个Topic包含一个或多个Partition
- Partition:存储消息的单元,由Topic创建,分leader partition和follower partition
- Consumer:从订阅的Topic主动拉取消息并消费
- ZooKeeper:维护集群节点状态信息
- Producer和Consumer的请求,都是由leader partition处理
Topic 与 Partition
- 分区策略:顺序分发、Hash分区
- 每个Partition即是一个文件夹,包含.index、.log文件,读取消息时:
- 1、从.index文件获取消息在.log文件中的offset值
- 2、从.log文件的offset位置开始读取消息
- 3、消息定长,即到offset+len(消息定长)处结束读取
数据一致性
- ISR(in-sync Replica):与leader数据保持一定程度同步的follower
- OSR:与leader数据滞后过多 的follower
- LEO:每个副本(Leader 和 Follower)消息偏移量
- HW:所有副本(Leader 和 Follower)的LEO最小值,Consumer只能读取HW之前的消息
producer生产消息至leader partition后,HW和LEO变化过程:
1、Producer向broker发送消息

2、Leader更新LEO,Follower开始同步Leader消息
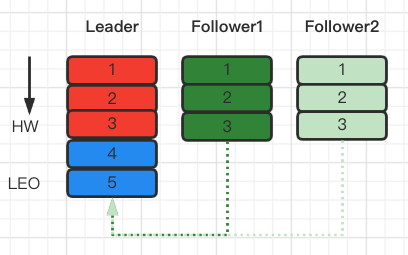
3、其中一个Follower完全同步了Leader的消息,另一个只同步了部分消息

4、所有的Follower完成消息同步
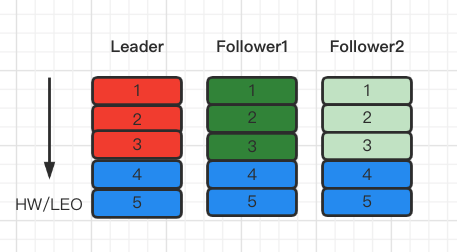
故障转移
- 1、producer提交消息时,同步ISR中的一定数量的follower,才会回复ACK
- 2、ZooKeeper维护节点的alive状态
- 3、leader所在节点宕机后,从ISR列表中选举一个follower节点成为leader
可用性和持久性保证
- 1、禁用unclean leader选举机制:ISR副本全部宕机情况下,不允许非ISR副本选举leader
- 2、指定最小的ISR集合大小,只有当ISR的大小大于最小值,分区才能接受写入操作
消费者组
每个分区只能由同一个消费组内的一个consumer来消费
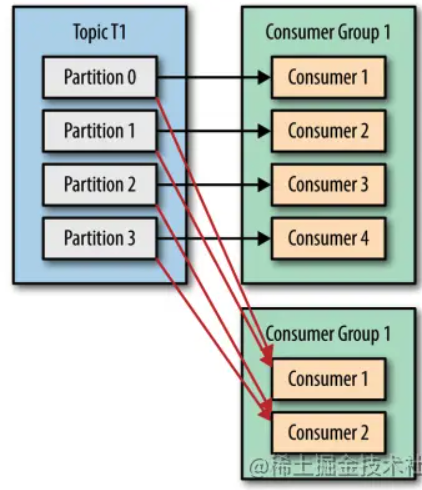
offset管理
- 由消费者客户端提交
- 早期放在Zookeeper,后来放在专用topic
Q&A
如何保证消息传输?
- broker commit成功,有副本机制(replication)的存在,保证消息不丢
- broker commit不成功,producer会重试,可能导致重复消息
如何保证消息顺序?
- 同一个partition消息是有序的
- 不同partition消息无序
为什么Producer不在Zookeeper中注册?
- Producer直接由Broker中的Coordinator协调、管理,并进行rebalance
- 减少Zookeeper的rebalance负担
如何保障Kafka吞吐率?
- partition顺序读写磁盘
- broker持久化数据采用mmap页缓存
- customer从broker读取数据采用0拷贝(sendfile)
- broker数据批处理,压缩,减少io,非强制刷新缓存写操作
- customer并行读取partition消息
- https://xie.infoq.cn/article/49bc80d683c373db93d017a99
消费者获取消息是pull,而不使用push?
- 消费者根据自身的处理能力去拉取消息并处理,若采用push方式,可能会push消息速率过高而压垮消费者
kafka怎么保证数据 一致性?
- 引入ISR、OSR、LEO、HW
- 既不是完全的同步复制,也不是单纯的异步复制,平衡吞吐量和确保消息不丢(同步几个副本才会回复ack,可配置)
为什么不采用Quorum读写机制?
1 2 3 4
Quorum(法定人数)读写机制常用于分布式系统中,保证数据一致性和可用性(避免脏读)。核心思想是通过设定读写操作节点数阀值,确保系统在部分节点失效情况下,扔能维持数据一致性。 - W(Write Quorum):写操作至少成功副本数 - R(Read Quorum):读操作至少成功副本数 - 总副本数N,Quorum规则要求:W + R > N;也就是读写操作存在交集副本,从而保证至少能读到一个最新数据副本
- 优点:保证可用性,系统在部分节点不可用情况下,扔能维持数据一致性
- 缺点:延迟取决与最慢的节点
- 缺点:多数的节点挂掉不能选择 leader
- 缺点:单点故障需要3份数据,要冗余2个故障需要5份,降低吞吐量,大数据量下成本高
ZooKeeper高可用?
v2.8版本后移除ZooKeeper,采用KRaft方式
- raft协议:https://xie.infoq.cn/article/57da6912139339e5098afb9cb
参考
- Kafka 详解:https://www.modb.pro/db/105106
- 官文-设计思路:https://kafka.apachecn.org/documentation.html#design
- kafka为什么这么快:https://xie.infoq.cn/article/49bc80d683c373db93d017a99
- Kafka 的基础架构:https://xie.infoq.cn/article/eabce320fb1d710db0e4fc9f9
This post is licensed under CC BY 4.0 by the author.