MySQL
MySQL
范式
1NF:原子性,列不可以再拆分。
2NF:1、表必须有主键。2、非主键列必须完全依赖主键,而不能只依赖主键的一部分。
1 2 3
例:订单明细表:【OrderDetail】(OrderID,ProductID,UnitPrice,Discount,Quantity,ProductName)。 因为我们知道在一个订单中可以订购多种产品,所以单单一个 OrderID 是不足以成为主键的,主键应该是(OrderID,ProductID)。显而易见 Discount(折扣),Quantity(数量)完全依赖(取决)于主键(OderID,ProductID),而 UnitPrice,ProductName 只依赖于 ProductID。所以 OrderDetail 表不符合 2NF。不符合 2NF 的设计容易产生冗余数据。 可以把【OrderDetail】表拆分为【OrderDetail】(OrderID,ProductID,Discount,Quantity)和【Product】(ProductID,UnitPrice,ProductName)来消除原订单表中UnitPrice,ProductName多次重复的情况。
3NF:在满足2NF的情况下,非主键列必须直接依赖主键,而不能依赖非主键类。也就是不能传递依赖。
反三范式:为了优化查询效率,可以增加冗余字段。
参考
- https://thinkwon.blog.csdn.net/article/details/104778621
- 三范式:https://blog.csdn.net/Dream_angel_Z/article/details/45175621
引擎
| MyISAM | Innodb | |
|---|---|---|
| 外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 锁粒度 | 表级锁 | 行级锁、表级锁 |
| CURD | select更优 | insert、update、delete更优 |
| 索引 | 1、不支持哈希索引 2、支持全文索引 3、非聚簇索引 4、索引叶子节点存储的是行数据地址,需要再次寻址才能得到数据 | 1、支持哈希索引 2、不支持全文索引 3、聚簇索引 4、主键索引的叶子节点存储行数据,不需要再次寻址 |
| 场景 | 以读为主的应用程序,如博客、新闻 | 更新、删除频繁的应用,如op系统 |
索引类型
- 主键索引
- 普通索引
- 唯一索引
- 组合索引
- 全文索引
主键索引、普通索引的区别
- 主键索引B+树叶子节点存放整行数据,聚簇索引
- 普通索引B+树叶子节点存放索引项-主键映射关系,需要回表查询,非聚簇索引
覆盖索引
- 作用在联合索引
- 当查询的所有字段都在索引中,直接在索引文件就可以读到数据,不需要回表查询
- explain:extra列可以看到using index
- https://juejin.cn/post/6844903967365791752
聚簇索引、非聚簇索引
- 聚簇索引:数据和索引放在一起,找到了索引也就找到数据,不需要回表查询。如Innodb的主键索引
- 非聚簇索引,数据和索引是分开的,索引结构只是保存了指向数据对应的行,需要回表查询。如MyISAM的B+tree索引结构
索引数据结构
b+tree
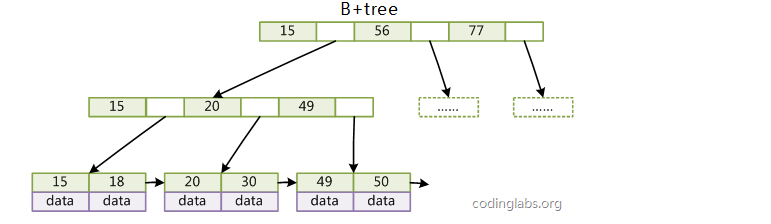
- 大多数情况下走的是b+tree索引
- 非叶子节点不保存数据
- 所有数据都保存在叶子节点
- 叶子节点形成有序的列表结构,方便范围查询
b-tree
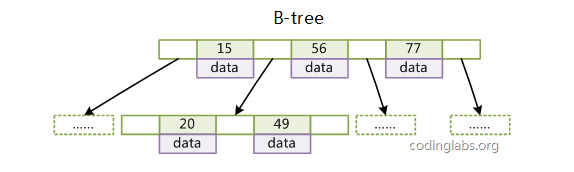
- 所有叶子节点都有保存key和数据
为什么使用b+tree,而不是b-tree
- b+tree非叶子节点存储更多的元素,IO查询次数更少
- 所有的查询都到叶子节点,性能更稳定
- 叶子节点形成有序链表,便于范围查询
索引使用场景
- where
- order by
- join…on…
索引使用方式
- 全值匹配最佳
- 复合索引要遵从 最佳左前缀法则
- 在索引列上操作(计算、函数、类型转换),引起索引失效
- 范围查询(bettween/</>/in)右边的列索引失效(当前列有效)
- select尽量覆盖索引列
- is null、is not null、!=、<>、or 导致索引失效
- like 以通配符开头(’%字符串’)导致索引失效
事务
- 是数据库操作的基本单位,要么都执行、要么都不执行
事务特性(ACID)
- 原子性(Atomicity):是数据的执行单位,不可再分割,事务要么全部执行,要么全部失败;基于undo log实现
- 一致性(Consistency):执行事务前后,数据保持一致,多个事务对同一个数据读取结果是相同的;通过回滚(undo log)、恢复(redo log)、锁、MVCC实现一致性
- 隔离性(Isolation):事务之间互不干扰,并发事务之间各自独立;基于锁机制和MVCC使事务相互隔离
- 持久性(Durability):事务提交之后,对数据库的改变是持久的;基于redo log日志持久化实现
脏读、不可重复读、幻读
脏读:一个事务读取了另一个事务未提交的数据
不可重复读:一个事务的两次读取同一分数据,两次的结果不一样,原因是在这两次读取之间,另一个事务对这份数据修改了
幻读(虚读):一个事务的两次读取一个范围内的数据,两次的结果不一样,原因是在这两次之间,另一个事务对这范围内的数据新增、删除了几行数据。
1 2
1、不可重复读、幻读是读取了另一个已经提交了的事务,脏读是读取未提交的事务 2、不可重复读是针对一条数据,幻读是一批数据
事务隔离级别
读取未提交:允许读取未提交的事务,可导致脏读
读取已提交:允许读取已提交的事务,可导致不可重复读、幻读
可重复读:同一行数据多次读取的结果是一致的,可导致幻读
串行化:最高隔离级别,所有事务依次执行,可防止脏读、不可重复读、幻读
1 2 3
1、事务隔离机制实现是基于锁和并发调度 2、MySQL默认隔离级别是可重复读 3、PostGreSQL默认隔离级别是读已提交
锁
- 事务并发情况下,锁实现了事务的执行次序
锁分类
- 功能分
- 读锁(共享锁)
- 写锁(排他锁)
- 粒度分
- 行锁:
- 页级锁:
- 表锁:MyISAM采用表锁
隔离级别和锁
- 读未提交:读取数据不需要加共享锁
- 读已提交:读操作加共享锁,读语句执行完以后就释放共享锁
- 可重复读:读操作加共享锁,读语句执行完以后不释放共享锁,事务结束后释放共享锁
- 可串行化:事务加排他锁。
乐观锁、悲观锁
- 乐观锁:在需要修改数据之前,先查一下数据是否被修改过。一般是用版本号实现。适合读多写少的场景。
- 悲观锁:基于数据库的锁机制。适合写多读少的场景。
间隙锁
- 加锁在空闲空间,可以是两索引之间,也可以第一个索引之前或最后一个索引之后
- 防止幻读
优化
大表数据优化
- 优化表、SQL、加索引
- 加缓存
- 主从复制、读写分离
- 垂直分表
- 水平分表
超大分页处理
减少load的数据量
1 2 3 4 5 6 7
【推荐】利用延迟关联或者子查询优化超多分页场景。 说明:MySQL并不是跳过offset行,而是取offset+N行,然后返回放弃前offset行,返回N行,那当offset特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行SQL改写。 正例:先`select id from 表1 where 条件 LIMIT 100000,20 `快速定位需要获取的id段,然后再关联: SELECT a.* FROM 表1 a, (select id from 表1 where 条件 LIMIT 100000,20 ) b where a.id=b.id
滚动加载,这样可以记录上一次的id, 用
where id >上一页的id
慢查询优化(重要)
- 分析语句,是否load多余的行然后抛弃掉;是否查询了多余的列
- explain分析执行计划,然后修改语句、修改索引
- 表数据量太大,加缓存,分表,读写分离
主从复制
方式
- 基于SQL(SBR)
- 优点:binlog比较小
- 缺点:不是所有的update语句都被复制
- 基于行复制(RBR)
- 优点:安全可靠
- 缺点:binlog太大
- 混合模式复制(MBR)
- 基于SQL(SBR)
原理
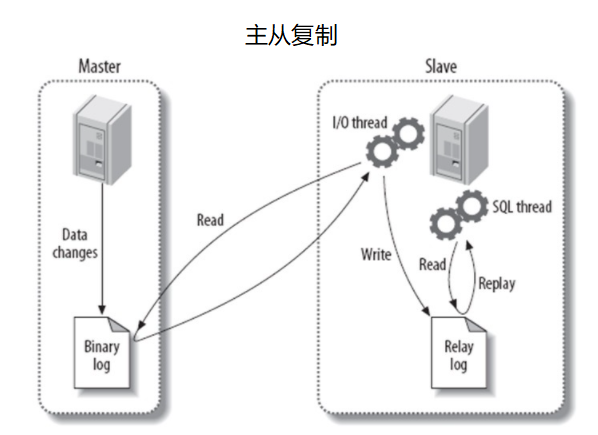
主服务binlog线程把操作记录记录到binlog文件
从服务I/O线程把主服务的binlog同步到从服务中继日志
从服务的SQL执行线程读取中继日志,写入数据库
1 2 3 4 5 6 7 8
1、两个日志 主:binlog日志 从:中继日志 2、三个线程 binlog线程:主,记录主服务的操作记录到binlog日志 I/O线程:从,拉取主服务的binlog日志到中继日志 SQL执行线程:从,执行中继日志,数据写入从服务
字符串的排序规则
- 基于字符集的排序
性能分析的命令方法
- show status 一些监控的变量值
- Bytes_received/Bytes_send 服务器的来往流量
- com_*:正在执行的命令
- Created_*:在执行期间创建的临时表、文件
- Select_*:不同类型的执行计划
- show profile 是MySQL用来分析当前会话SQL语句的执行资源消耗情况
一条SQL语句在MySQL中的执行过程
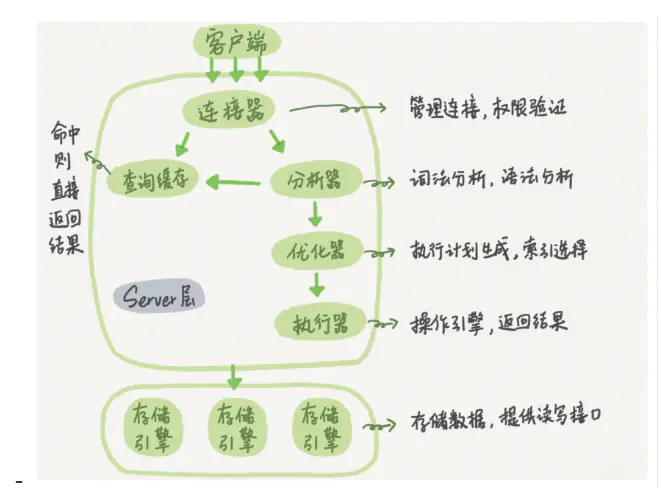
- 1、客户端通过TCP连接到服务端
- 2、连接器做权限认证
- 3、查询缓冲,命中则直接返回
- 4、分析器做词法分析
- 5、优化器确认执行计划
- 6、执行器操作存储引擎
- 7、存储引擎进行curd
MySQL基础架构
- 第一层:连接管理,授权认证,安全等
- 第二层:编译和优化SQL
- 第三层:存储引擎
count(*), count(1), count(列名)
- count(*):包含所有列,统计结果是所有的行数
- count(1):1表示忽略所有的列,统计的结果是所有的行数
- count(列名):统计列名的那一列,统计的结果是该列值不为null的数量
触发器的类型
- Before Insert
- After Insert
- Before Update
- After Update
- Before Delete
- After Delete
约束类型
- not null:不能为null
- unique:唯一约束
- primary key:主键约束
- foreign key:外键,级联删除等
- check:用于控制字段的范围
union与union all的区别
- union:对两个结果集进行并集操作,不包括重复行,同时进行排序
- union all:对两个结果集进行并集处理,包括重复项
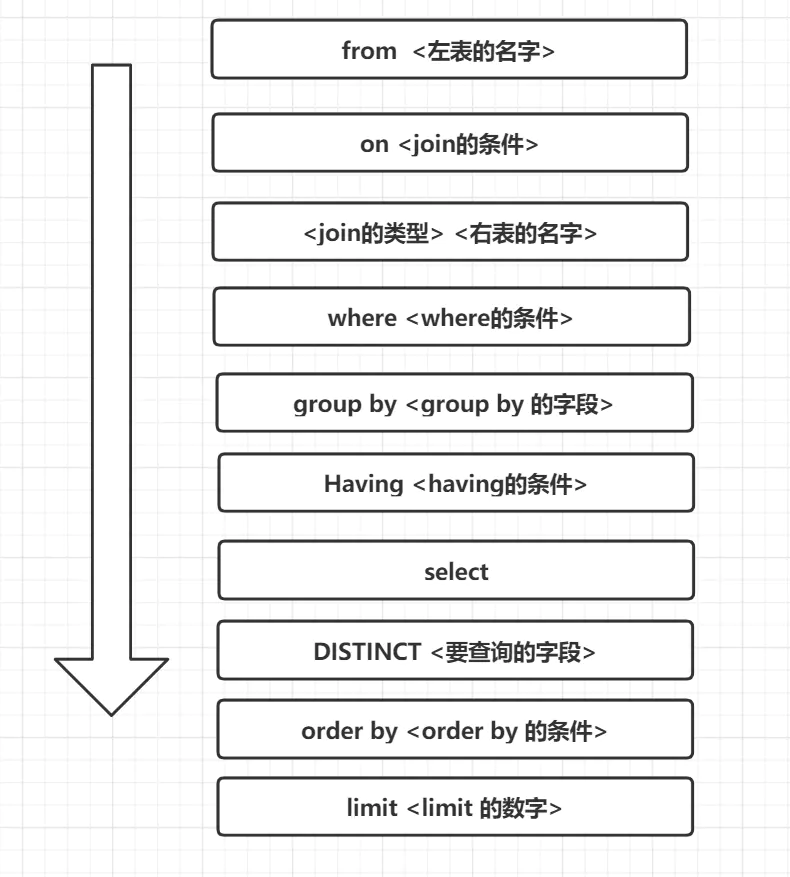
SQL执行顺序
expain的字段
- id: SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符.
- select_type: SELECT 查询的类型.
- table: 查询的是哪个表
- partitions: 匹配的分区
- type: join 类型
- possible_keys: 此次查询中可能选用的索引
- key: 此次查询中确切使用到的索引.
- ref: 哪个字段或常数与 key 一起被使用
- rows: 显示此查询一共扫描了多少行. 这个是一个估计值.
- filtered: 表示此查询条件所过滤的数据的百分比
- extra: 额外的信息
1
比较关注的字段:type、key、rows
uuid性能低下的原因
- uuid无序,建立b+tree时效率低
- uuid占用内存多,I/O效率低
- 字符串连表性能差
参考
- MySQL索引背后的数据结构及算法原理:https://blog.codinglabs.org/articles/theory-of-mysql-index.html
- MySQL面试汇总:https://thinkwon.blog.csdn.net/article/details/104778621
- 索引:https://blog.csdn.net/wuseyukui/article/details/72312574
This post is licensed under CC BY 4.0 by the author.