Redis
Redis
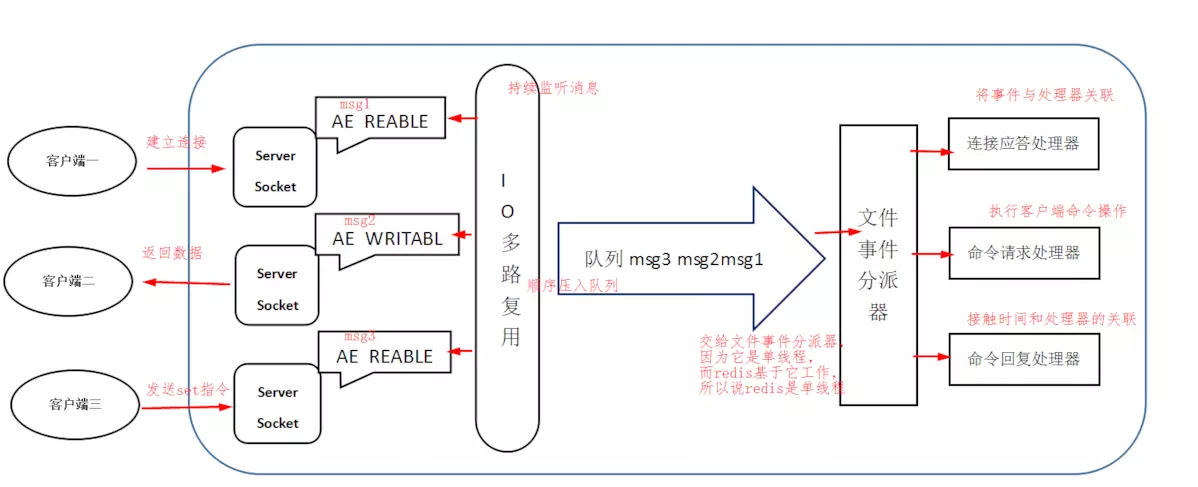
线程模型
发布订阅
命令
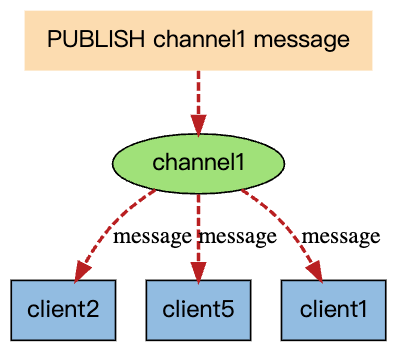
- publish:发布消息到channel
- subscribe:订阅一个channel
实现原理
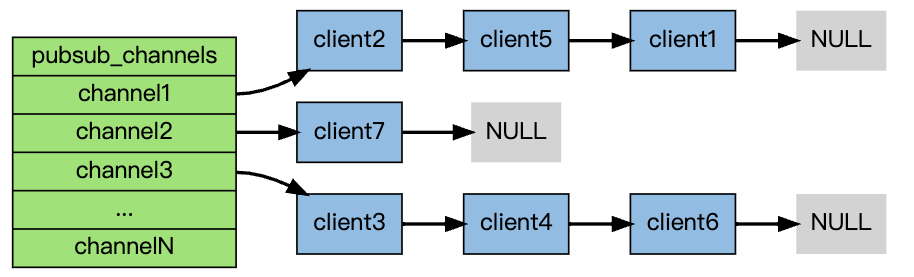
redis以字典保存channel,键是channel,值为订阅该channel的链表
持久化机制
RDB:以固定的时间,将内存中的数据以快照的形式保存到硬盘中
AOF:每个redis的命令请求,通过追加的方式保存到aof文件
1 2 3 4
优缺点 1、AOF比RDB更新更频繁,aof文件更大 2、AOF安全型更好 3、RDB性能更好
过期键删除策略
- 定时过期:每个设置过期时间的 键 都会创建一个定时器,到了过期时间立即清除。这种方式对内存友好,耗CPU。
- 定期过期:每隔一段时间就会扫描一定数量设置过期时间的 键。
- 惰性过期:当访问 键 时,判断键是否过期,过期则删除。这种方式对CPU友好,但占内存。
内存淘汰策略
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。默认策略
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。
allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
1 2 3 4
(重点) LRU淘汰:最近最少使用(访问时间),该算法根据数据的历史访问记录进行淘汰。思想是“如果数据最近被访问过,那么将来被访问的几率也更高 TTL淘汰:优先淘汰更快过期的键 随机淘汰:对redis中的键随机淘汰
事务
- multi(开启事务)、exec(执行事务)、discard(取消事务)
- 三个阶段:事务开始、命令入队、执行事务
- 事务不支持回滚
- 若一个事务中命令拼写错误
如:getk1,则事务中的所有命令都不执行 - 若一个事务中命令执行错误
如:incr k1,(k1的值为字符串),则事务中其他正确命令都执行
lua脚本
- redis内部嵌入了lua脚本解释器
- lua脚本的命令执行是原子性
管道
- 减少RTT,提高QPS
- 不是原子性
缓存异常
缓存雪崩
- 定义:缓存在同一时间大面积失效,请求直接访问数据库,数据库短时间内承受大量的请求而崩掉
- 解决
- 设置缓存过期时间为随机数
- 设置多级缓存
- 利用加锁或者队列方式避免过多请求同时对服务器进行读写操作(串行)
缓存穿透
定义:指缓存和数据库都没有该数据,导致请求直接访问数据库,数据库短时间内承受大量请求而崩掉
解决
对应null值也做缓存
采用布隆过滤器,将所有可能存在的数据哈希到一个bitmap中,一定不存在的数据会被这个bitmap过滤掉
1
随着数据库中的用户量增长,也去更新布隆过滤器
缓存击穿
定义:缓存中没有但数据库中有的数据,大并发量的请求读取缓存没有读取到数据而访问数据库,导致数据库瞬间压力过大。
1
和缓存雪崩不同的是,缓存击穿是指一条数据,缓存雪崩是指大批量数据缓存同时是过期
解决
- 热点数据永不过期
布隆过滤器
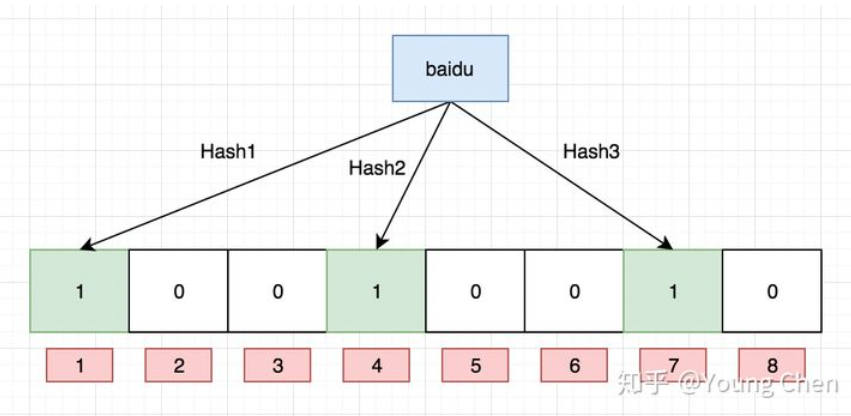
- 判断一个value一定不存在或者可能存在
- 一个bit数组 + 三个hash函数
缓存更新方式
- 先更新数据库,再更新缓存
- 若更新数据库成功,更新缓存失败,会导致脏读
- 先删除缓存,在更新数据库
- 假设更新操作先删除了缓存,此时正好有一个并发的读操作,没有命中缓存后从数据库中取出老数据并且更新回缓存,这个时候更新操作也完成了数据库更新。此时,数据库和缓存中的数据不一致,应用程序中读取的都是原来的数据(脏数据)。
- 先更新数据库,在删除缓存
- 推荐使用的方式,理论上还是可能存在问题
- 写操作慢于读操作
版本新特性
- 6.0
- 多线程IO(执行命令仍然是单线程)
- 1、IO 线程要么同时在读 socket,要么同时在写,不会同时读或写
- 2、IO 线程只负责读写 socket 解析命令,不负责命令处理
- 支持SSL
- 多线程IO(执行命令仍然是单线程)
- 5.0
- 新增流数据类型(stream data type)
- RDB可存储LFU和LRU
- 4.0
- 新增LFU
参考
- https://thinkwon.blog.csdn.net/article/details/103522351
- 内存淘汰策略:https://www.jianshu.com/p/aa05f899aaf1
- 缓存模式:https://blog.csdn.net/weixin_45439324/article/details/103372329
- 布隆过滤器:https://www.cnblogs.com/heihaozi/p/12174478.html
This post is licensed under CC BY 4.0 by the author.